Machine Language: Count Faster on 6502
By Michael Doornbos
- 7 minutes read - 1289 wordsI’ve done a lot of silly math, ciphers and asked a lot of my vintage hardware on this site over the years. But I’ve not talked a ton about optimizing code for faster results.
Today, we will count from 0 to 2^24-1 (16,777,215). Nothing else. Count, time it, and see how fast we can get it to go.
Rust
In Rust on my 2020 MacBook Pro:
use std::time::{Instant};
fn main() {
// Start timing
let start = Instant::now();
// Loop from 0 to 16777215
for _i in 0..=16777215 {
// The loop body is empty, just like in the BASIC code
}
// Calculate elapsed time
let duration = start.elapsed();
// Convert elapsed time to seconds
let elapsed_seconds = duration.as_secs() as f64
+ (duration.subsec_nanos() as f64 / 1_000_000_000.0);
println!("Counting to 16777215 took {} seconds", elapsed_seconds);
println!("That's {} additions per second", 16777216.0 / elapsed_seconds);
println!("On 2 GHz Quad-Core Intel Core i5")
}
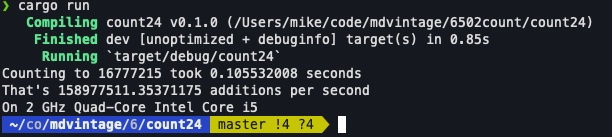
It’s so fast I gave ZERO thought to optimzing futher. Interesting if you’re into blazing speed I suppose.
Commodore 64 BASIC
Slower machines are great for learning optimization because the results can be dramatic. And when we need slow, the best tool is BASIC!
Better grab some coffee. And lunch. And maybe an afternoon snack. Also, go to the gym and walk the dog…
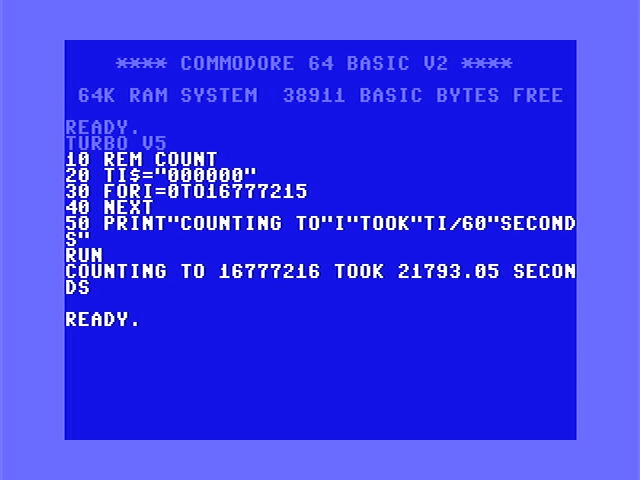
Well, that took a while.
Let’s turn off the screen. The VIC-II steals time from the CPU quite often, so let’s turn it off and see what happens.
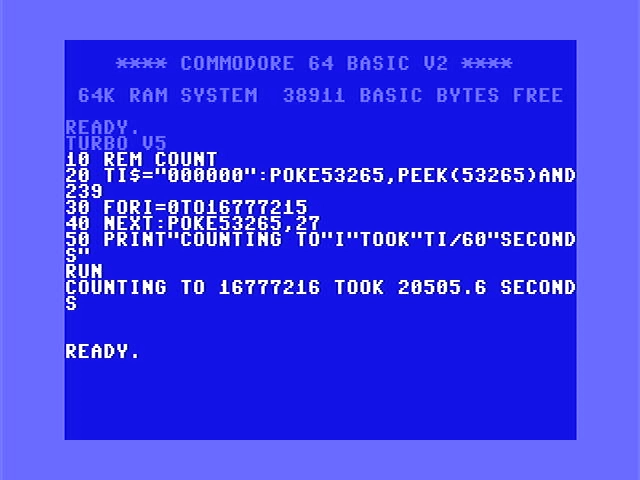
It IS 6% faster.
The Commodore 64 uses a variant of the 6502 processor, the 6510. I’m going to use the term 6502 to refer to both processors. Also, I did these two BASIC tests on an Ultimate 64 because I couldn’t bring myself to ask a 40 year old machine to sit in a loop incrementing for 24 hours to get these results. THINK OF THE CHILDREN!
Assembly
Naturally, we must turn to assembly language to make this more palatable. All day isn’t going to work.
Some housekeeping: I wrapped all of the following code sections with a couple of things that I don’t show here to keep this post from being the length of a novel:
- Disabled interrupts
- Changed the screen colors
- Printed the count bytes to make sure they end up at
FFFFFF - Printed the Commodore 64 Jiffy count that it took to complete in hexadecimal
The output screen, when done, looked like this:
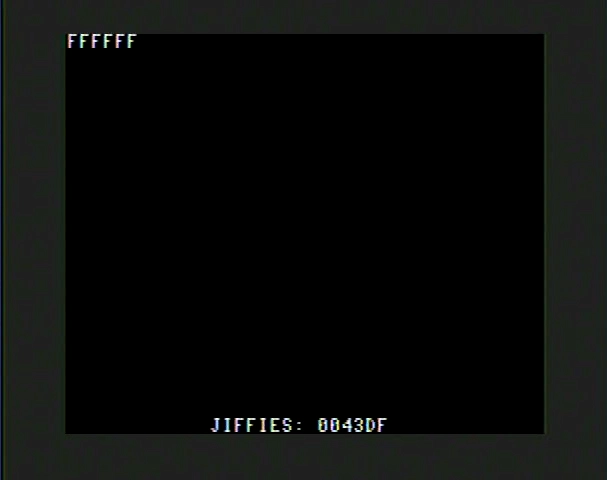
Nothing fancy. Just a quick and dirty way to get the results for each of these tests.
I used a breadbin C64 with all original parts except the PLA, which is a drop-in replacement on this motherboard as the original is in PLA heaven.
The one one the right is the test machine for all of these.

This code is all formatted for Turbo Macro Pro, so if you use a different assembler, you may have to make minor adjustments for your weapon of choice.
Method 1
My first approach is along the lines of the way my brain works:
counter
clc
lda count
adc #$01
sta count
lda count+1
adc #$00
sta count+1
lda count+2
adc #$00
sta count+2
lda count+2
cmp #$ff
bne counter
lda count+1
cmp #$ff
bne counter
lda count
cmp #$ff
bne counter
Took 751 Seconds. Not bad, but not great.
The VIC-II steals time from the CPU quite often, so let’s turn the screen off and see what happens.
; disable screen
lda $d011
and #$ef
sta $d011
;------------------------------
; Do stuff here
;------------------------------
; re-enable screen
lda $d011
ora #$10
sta $d011
Took 703 Seconds. Hmm.
The three bytes we’re using here are in “high memory.” The 6502 accesses the zero-page addresses MUCH faster. What if we put those 3 bytes we’re incrementing in zero page?
Move
count .byte 0,0,0
to
count = $fb
Took 583 Seconds. Still better…
We’re doing a lot of needless checking. Let’s iterate and try again.
Method 2
We can reduce the number of checks by looking for the carry bit to be clear on each addition. That could eliminate thousands of checks.
counter
clc
lda count
adc #$01
sta count
bcc ahead
lda count+1
adc #$00
sta count+1
bcc ahead
lda count+2
adc #$00
sta count+2
ahead
lda count+2
cmp #$ff
bne counter
lda count+1
cmp #$ff
bne counter
lda count
cmp #$ff
bne counter
It took 441 seconds with the screen on, 412 seconds with the screen off, and 289 seconds with the screen off and zero page.
Much better, but let’s keep going.
Method 3
inc is fewer cpu cycles than adc, so let’s try using that opcode instead:
counter
inc count
bne done
inc count+1
bne done
inc count+2
done
lda count+2
cmp #$ff
bne counter
lda count+1
cmp #$ff
bne counter
lda count
cmp #$ff
bne counter
Took 331 seconds with the screen on, 310 seconds with the screen off and 275 seconds with the screen off and zero page.
Method 4
Credit is due to Gregorio Nacu for this one, who pointed out that we really only need to check if we’re done when we increment the high bit
counter3
inc count
bne counter3
inc count+1
bne counter3
inc count+2
lda count+2
cmp #$ff
bne counter3
counter2
inc count
bne counter2
inc count+1
lda count+1
cmp #$ff
bne counter2
counter1
inc count
lda count
cmp #$ff
bne counter1
It took 165 seconds with the screen on, 155 seconds with the screen off, and 138 seconds with the screen off and zero page.
Method 5
This one came from both David Youd and Robin Harbron within minutes of each other. They both pointed out that if you didn’t want to stop at an arbitrary value and only wanted to get right to before all three overflow, you could check for the overflow and be off by one.
Then Robin added the dec idea, which we’re calling the “slam on the brakes and throw her in reverse” method.
This only works for counting to the max value, but keep this in your toolbox for those cases. It might be helpful.
counter
inc count
bne counter
inc count+1
bne counter
inc count+2
bne count24
done
dec count
dec count+1
dec count+2
It took 165 seconds with the screen on, 155 seconds with the screen off, and 110 seconds with the screen off and zero page.
Keep going?
When we started, we were at 751 seconds. We’re now down to 110 seconds. That’s a 583% improvement.
At this point, I’m pretty happy with these results. There are a couple more things we could consider, but I will encourage you to try those. IF you can beat these times, please let me know. I’d love to see what you come up with. And show your work, none of this “back in my day, we did it this way, and it was faster” stuff. If you’re gonna brag, you gotta prove it.
I dare you. Or do it for fun. Or science. Or whatever. Just do it.
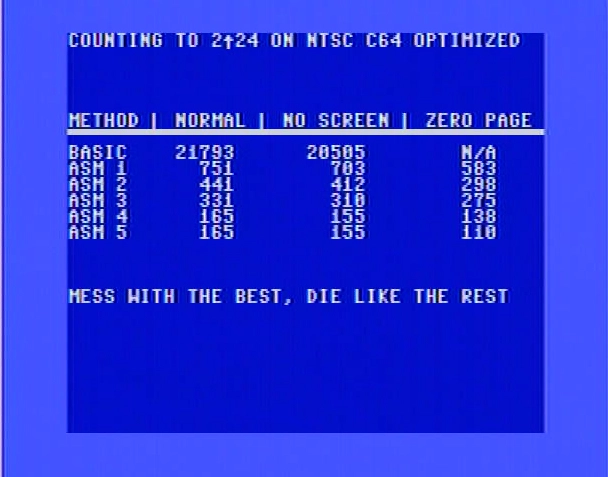
Results
| Method | Time (seconds) | Time w/Screen Blanked (seconds) | Blanked with Zero Page (seconds) |
|---|---|---|---|
| BASIC | 21793 | 20506 | N/A |
| ASM 1 | 751 | 703 | 583 |
| ASM 2 | 441 | 412 | 289 |
| ASM 3 | 331 | 310 | 275 |
| ASM 4 | 165 | 155 | 138 |
| ASM 5 | 165 | 155 | 110 |
This is an NTSC C64. PAL could be a little slower.
I was surprised that methods 4 and 5 were the same number of jiffies for the two non-zero page tests. $26bf(9919) and $2447 (9287)
We might have to do a follow-up post to explain why that is.
Thanks to:
Many thanks to Robin, David, Gregorio, and Adam for discussing on X and Signal on this one. I had way more fun on this because of you guys than if I had just done it one my own.
- C64
- Code
- Commodore
- Getting Started
- How-To
- Retro
- 6502
- Assembly
- Machine Language
- Programming
- Programming Languages