The Wallis Product for Pi on the C64
By Michael Doornbos
- 13 minutes read - 2558 wordsHappy Pi Day. The Wallis product is one of the oldest formulas for pi. It’s also one of the slowest.
In 1655, John Wallis published this:
$$\frac{\pi}{2} = \frac{2}{1} \cdot \frac{2}{3} \cdot \frac{4}{3} \cdot \frac{4}{5} \cdot \frac{6}{5} \cdot \frac{6}{7} \cdot \frac{8}{7} \cdot \frac{8}{9} \cdots$$Each pair of fractions uses the same even number on top. The denominators are the odd numbers on either side. Multiply enough of these together and you get pi/2.
You can write the whole thing more compactly as a single product:
$$\frac{\pi}{2} = \prod_{n=1}^{\infty} \frac{4n^2}{4n^2 - 1}$$That’s it. One formula, one loop, and pi falls out the other end.
How Slow?
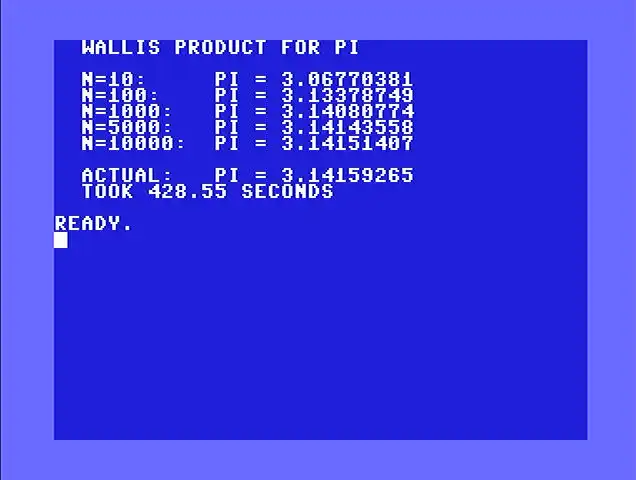
The Wallis product converges like $O(1/n)$. After 10 terms you get 3.067. After 100 terms, 3.133. After 1,000 terms, 3.140. You need about 10,000 terms to reach 3.1415, and even that’s only four digits.
For comparison, the Gregory-Leibniz series converges at roughly the same rate. Machin’s formula gets 4 digits per term. The Wallis product is not practical for computing pi. But on a slow machine, you can watch every digit fight its way in.
BASIC
10 REM *** WALLIS PRODUCT FOR PI ***
20 REM *** BY MICHAEL DOORNBOS 2026 ***
30 REM *** IMAPENGUIN.COM ***
40 PRINT CHR$(147);
50 PRINT CHR$(5);
55 TI$="000000"
60 PRINT" WALLIS PRODUCT FOR PI"
70 PRINT
80 P=1
90 FOR N=1 TO 10000
100 P=P*(4*N*N)/(4*N*N-1)
110 IF N=10 THEN PRINT " N=10: PI =";2*P
120 IF N=100 THEN PRINT " N=100: PI =";2*P
130 IF N=1000 THEN PRINT " N=1000: PI =";2*P
140 IF N=5000 THEN PRINT " N=5000: PI =";2*P
150 NEXT N
160 PRINT " N=10000: PI =";2*P
170 PRINT
180 PRINT " ACTUAL: PI = 3.14159265"
190 PRINT " TOOK"TI/60"SECONDS"
Line 100 does all the work. Each iteration multiplies the running product by $4n^2 / (4n^2 - 1)$. The IF statements at lines 110-140 print snapshots so you can watch the convergence.
Line 55 zeros the jiffy clock by setting TI$ to "000000". The C64 increments TI sixty times per second, so TI/60 at line 190 gives elapsed seconds.
BASIC V2 uses 5-byte floats with about 9 digits of precision. The Wallis product won’t exceed that precision in 10,000 terms, so the C64’s math is accurate here. The limiting factor isn’t the hardware, it’s the formula itself. Each new term only nudges the product a tiny bit closer to pi. After 10,000 terms we still only have four correct digits, not because the C64 ran out of precision, but because the Wallis product just hasn’t gotten there yet. A faster computer running the same 10,000 terms would get the same four digits, only sooner.
This takes a while in BASIC. Each of those 10,000 iterations involves two multiplications, a subtraction, and a division, all parsed from text at runtime. On real hardware, expect about five and a half minutes.
Assembly
Assembly calls the BASIC ROM’s floating-point routines directly instead of going through the interpreter. The algorithm is identical to the BASIC version. If you want the full story on these routines, Sheldon Leemon’s Mapping the Commodore 64 covers the float engine in detail (p.212-232). Here’s what we use:
| Routine | Address | What it does |
|---|---|---|
| MOVFM | $bba2 |
Load FAC from 5-byte float at address A/Y |
| MOVMF | $bbd4 |
Store FAC to 5-byte float at address X/Y |
| FMULTT | $ba28 |
FAC = mem(A/Y) × FAC |
| FADDT | $b867 |
FAC = mem(A/Y) + FAC |
| FDIVT | $bb0f |
FAC = mem(A/Y) ÷ FAC |
| GIVAYF | $b391 |
Signed 16-bit integer (A=high, Y=low) to FAC |
| FOUT | $bddd |
Convert FAC to ASCII string at $0100 |
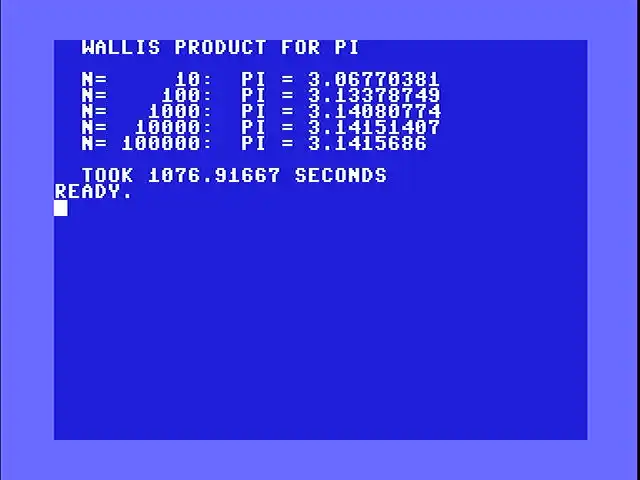
The loop multiplies the running product by $4n^2$ first, then divides by $4n^2 - 1$. This matches the order BASIC uses when it evaluates P=P*(4*N*N)/(4*N*N-1) left to right. The order matters for precision: if you compute the ratio $4n^2 / (4n^2 - 1)$ first, you get a number so close to 1.0 that the C64’s 9-digit floats can barely tell it apart from 1. Multiplying by the large numerator first keeps more significant digits in play. A milestone table triggers printing the current pi estimate at n=10, 100, 1,000, 10,000, and 100,000.
The assembly version runs 10x further than BASIC because it can afford to. At 100,000 iterations, the C64’s 9-digit floats still have enough precision to give five correct digits of pi. The whole thing finishes in about 912 seconds (just over 15 minutes) on real hardware.
; ==============================
; wallis product for pi
; by michael doornbos 2026
; mike@imapenguin.com
;
; pi/2 = product of 4n^2/(4n^2-1)
; uses basic rom float routines
; prints results at milestones
; runs to 100000 iterations
; ==============================
* = $c000
; rom routines
chrout = $ffd2
movfm = $bba2
movmf = $bbd4
fmultt = $ba28
faddt = $b867
fdivt = $bb0f
; zero page
ptr = $fb
; --- entry ---
lda #$93
jsr chrout
lda #5
jsr chrout
; print title
ldx #<stitle
ldy #>stitle
jsr print
lda #13
jsr chrout
lda #13
jsr chrout
; zero jiffy clock
sei
lda #0
sta $a0
sta $a1
sta $a2
cli
; product = 1.0
ldx #4
cpone lda fpone,x
sta product,x
dex
bpl cpone
; n = 1.0
ldx #4
cpn lda fpone,x
sta nval,x
dex
bpl cpn
; init 24-bit counter
lda #1
sta count
lda #0
sta count+1
sta count+2
; milestone pointer
lda #0
sta mptr
; --- main loop ---
loop
; fac = n
lda #<nval
ldy #>nval
jsr movfm
; fac = n * n
lda #<nval
ldy #>nval
jsr fmultt
; fac = 4 * n * n
lda #<fp4
ldy #>fp4
jsr fmultt
; save 4n^2
ldx #<temp
ldy #>temp
jsr movmf
; fac = product * 4n^2
lda #<product
ldy #>product
jsr fmultt
; compute 4n^2 - 1 as denominator
; save numerator first
ldx #<denom
ldy #>denom
jsr movmf
; load 1.0, then flip the sign byte
; at $66 to negate it
lda #<fpone
ldy #>fpone
jsr movfm
lda $66
eor #$ff
sta $66
; fac = 4n^2 + (-1) = 4n^2 - 1
lda #<temp
ldy #>temp
jsr faddt
; fac = (product * 4n^2) / (4n^2 - 1)
; fdivt does mem/fac
lda #<denom
ldy #>denom
jsr fdivt
; save product
ldx #<product
ldy #>product
jsr movmf
; check milestones
ldx mptr
cpx #15
bcs nocheck
lda count
cmp miles,x
bne nocheck
lda count+1
cmp miles+1,x
bne nocheck
lda count+2
cmp miles+2,x
bne nocheck
; hit a milestone
jsr showpi
; advance pointer by 3
lda mptr
clc
adc #3
sta mptr
nocheck
; n = n + 1
lda #<nval
ldy #>nval
jsr movfm
lda #<fpone
ldy #>fpone
jsr faddt
ldx #<nval
ldy #>nval
jsr movmf
; 24-bit count++
inc count
bne chkdn
inc count+1
bne chkdn
inc count+2
chkdn
; done at 100001 ($0186a1)?
lda count+2
cmp #$01
bcc notdone
bne chkhi
lda count+1
cmp #$86
bcc notdone
bne isdone
lda count
cmp #$a1
bcs isdone
jmp loop
chkhi jmp done
notdone jmp loop
isdone
done
; --- done ---
; read jiffy clock (24-bit)
sei
lda $a2
sta jiffies
lda $a1
sta jiffies+1
lda $a0
sta jiffies+2
cli
; print time in seconds
lda #13
jsr chrout
ldx #<stime
ldy #>stime
jsr print
; convert 24-bit jiffies to float
; byte-by-byte to stay unsigned
lda #0
ldy jiffies+2
jsr $b391
lda #<fp64k
ldy #>fp64k
jsr fmultt
ldx #<temp
ldy #>temp
jsr movmf
lda #0
ldy jiffies+1
jsr $b391
lda #<fp256
ldy #>fp256
jsr fmultt
lda #<temp
ldy #>temp
jsr faddt
ldx #<temp
ldy #>temp
jsr movmf
lda #0
ldy jiffies
jsr $b391
lda #<temp
ldy #>temp
jsr faddt
; divide by 60
; fdivt does mem/fac, so load 60
; into fac first
ldx #<temp
ldy #>temp
jsr movmf
lda #<fp60
ldy #>fp60
jsr movfm
lda #<temp
ldy #>temp
jsr fdivt
jsr fprint
ldx #<ssec
ldy #>ssec
jsr print
rts
; --- show pi subroutine ---
; prints nval (float n) and 2*product
showpi
ldx #<sn
ldy #>sn
jsr print
; print n right-justified to 7 chars
lda #<nval
ldy #>nval
jsr movfm
jsr fprintw
ldx #<spi
ldy #>spi
jsr print
; compute 2 * product without
; modifying stored product
lda #<product
ldy #>product
jsr movfm
lda #<fp2
ldy #>fp2
jsr fmultt
jsr fprint
lda #13
jsr chrout
rts
; --- print float right-justified ---
; pads to 7 chars wide
fprintw jsr $bddd
; find string length
ldy #0
fwlen lda $0100,y
beq fwpad
iny
bne fwlen
; pad with spaces to 7
fwpad cpy #7
bcs fwprnt
lda #32
jsr chrout
iny
jmp fwpad
; print the string
fwprnt ldy #0
fwloop lda $0100,y
beq fwdone
jsr chrout
iny
bne fwloop
fwdone rts
; --- print float in fac ---
; uses fout, no padding
fprint jsr $bddd
ldy #0
fploop lda $0100,y
beq fpdone
jsr chrout
iny
bne fploop
fpdone rts
; --- print subroutine ---
; x=lo, y=hi, null-terminated
print stx ptr
sty ptr+1
ldy #0
ploop lda (ptr),y
beq pdone
jsr chrout
iny
bne ploop
pdone rts
; --- strings ---
stitle .null " wallis product for pi"
sn .null " n="
spi .null ": pi ="
stime .null " took"
ssec .null " seconds"
; --- milestone table (lo/mid/hi) ---
miles
.byte <10, >10, 0
.byte <100, >100, 0
.byte <1000, >1000, 0
.byte <10000, >10000, 0
.byte <100000, >100000, $01
; --- float constants ---
fpone .byte $81,$00,$00,$00,$00
fp2 .byte $82,$00,$00,$00,$00
fp4 .byte $83,$00,$00,$00,$00
fp60 .byte $86,$70,$00,$00,$00
fp256 .byte $89,$00,$00,$00,$00
fp64k .byte $91,$00,$00,$00,$00
; --- variables ---
product .byte 0,0,0,0,0
nval .byte 0,0,0,0,0
temp .byte 0,0,0,0,0
denom .byte 0,0,0,0,0
count .byte 0,0,0
jiffies .byte 0,0,0
mptr .byte 0
Since 100,000 doesn’t fit in a 16-bit counter (max 65,535), the code uses a 24-bit count and 3-byte milestone entries. The showpi subroutine prints nval directly since it’s already a float tracking n. This sidesteps a gotcha with GIVAYF ($b391): it treats the 16-bit input as signed, so values above 32,767 come out negative.
FOUT ($bddd) converts FAC to a string at $0100 (the processor stack page, temporarily repurposed as a scratch buffer). The fprintw routine pads the result with leading spaces so the columns line up.
At the end, the jiffy clock conversion builds the float byte-by-byte (each byte is 0-255, always positive in GIVAYF), multiplies by 256 and 65,536, and adds them up. Dividing by 60 gives seconds. One gotcha here: FDIVT computes mem/FAC, not FAC/mem, so you have to save the jiffies total to memory, load 60 into FAC, then call FDIVT with the jiffies address. Get it backwards and you’ll see something like 1.097E-03 SECONDS instead of the actual time. Ask me how I know.
Run it with sys 49152.
Sanity Check
The C64 gives us 9 digits to work with. To verify those digits are right, and to see where the product goes with more precision, here’s the same algorithm in Python using 50-digit Decimal arithmetic.
#!/usr/bin/env python3
"""
Wallis product for pi
by michael doornbos 2026
mike@imapenguin.com
pi/2 = (2/1)(2/3)(4/3)(4/5)(6/5)(6/7)...
= product of 4n^2 / (4n^2 - 1) for n = 1, 2, 3, ...
"""
from decimal import Decimal, getcontext
getcontext().prec = 50
milestones = {10, 100, 1000, 10000, 100000, 1000000,
10000000, 100000000, 1000000000}
p = Decimal(1)
for n in range(1, 1000000001):
n2 = Decimal(4 * n * n)
p *= n2 / (n2 - 1)
if n in milestones:
print(f"n={n:>10}: pi = {2 * p}", flush=True)
print(f"\nactual: pi = 3.1415926535897932384626433832795028841971")
Output:
n= 10: pi = 3.0677038066434989710316881013507949531410
n= 100: pi = 3.1337874906281622412510360824623408115661
n= 1000: pi = 3.1408077460303945604858682015535018789750
n= 10000: pi = 3.1415141186819220469785580507138775513425
n= 100000: pi = 3.1415847996572463792125422767191607837912
n= 1000000: pi = 3.1415918681921207145964766814646445506447
n= 10000000: pi = 3.1415925750499818074560636751594175672245
n= 100000000: pi = 3.1415926457358116535755452294827963823084
n=1000000000: pi = 3.1415926528043950755560689255172666133465
After a billion terms, we have 3.14159265. Eight correct digits from a billion multiplications. The C64 assembly version pushes to 100,000 (getting five digits), which takes a few minutes on real hardware.
Let’s Do Some Serious Multiplication Now
A billion iterations in Python takes a while. In C with double precision, the same loop finishes in under a second.
/*
* wallis product for pi
* by michael doornbos 2026
* mike@imapenguin.com
*
* pi/2 = product of 4n^2 / (4n^2 - 1) for n = 1, 2, 3, ...
*
* compile: cc -O2 -o pi-wallis pi-wallis.c -lm
*/
#include <stdio.h>
#include <time.h>
int main(void)
{
long milestones[] = {10, 100, 1000, 10000, 100000,
1000000, 10000000, 100000000,
1000000000};
int nm = sizeof(milestones) / sizeof(milestones[0]);
int mi = 0;
double p = 1.0;
clock_t start = clock();
for (long n = 1; n <= 1000000000L; n++) {
double n2 = 4.0 * n * n;
p *= n2 / (n2 - 1.0);
if (mi < nm && n == milestones[mi]) {
printf("n=%10ld: pi = %.16f\n", n, 2.0 * p);
mi++;
}
}
double elapsed = (double)(clock() - start) / CLOCKS_PER_SEC;
printf("\ntook %.2f seconds\n", elapsed);
return 0;
}
Output:
n= 10: pi = 3.0677038066434985
n= 100: pi = 3.1337874906281620
n= 1000: pi = 3.1408077460304020
n= 10000: pi = 3.1415141186819566
n= 100000: pi = 3.1415847996572470
n= 1000000: pi = 3.1415918681921489
n= 10000000: pi = 3.1415925750808533
n= 100000000: pi = 3.1415926430662622
n=1000000000: pi = 3.1415926430662622
took 0.87 seconds
A billion terms in 0.87 seconds. But look at the last two lines. The value at 100 million and 1 billion is identical. Same number, nine more zeros on the iteration count, no improvement.
A C double stores 53 bits of mantissa, good for about 15-16 significant decimal digits. At each step, we multiply the running product by $4n^2 / (4n^2 - 1)$. When $n = 100{,}000{,}000$, that factor is:
That’s 1 followed by seventeen zeros before the first non-zero digit. A double can’t represent that. It rounds to exactly 1.0, and multiplying by 1.0 does nothing. Every iteration after that is a no-op. You could run a trillion iterations and the answer wouldn’t change.
The Python Decimal version with 50-digit arithmetic doesn’t have this problem, which is why it keeps improving all the way to a billion. The C64’s 9-digit floats hit the same wall much earlier. At $n = 10{,}000$, the per-step factor is about $1.000000025$, which is right at the edge of what a 5-byte float can distinguish from 1.0.
Every platform running the Wallis product hits this wall eventually. The only question is when:
| Platform | Precision | Wall hits around | Digits of pi |
|---|---|---|---|
| C64 BASIC/asm | 9 digits | $n = 10^4$ | 4 |
C double |
16 digits | $n = 10^8$ | 8 |
Python Decimal(50) |
50 digits | $n = 10^{25}$ | 25 |
You can push past it with arbitrary-precision libraries like GMP, but the convergence rate doesn’t get any better. The Wallis product converges at $O(1/n)$, so each new digit of pi costs ten times as many iterations. A billion terms gives 8 digits. A trillion would give 12. The Chudnovsky algorithm gets about 14 digits per term, which is why nobody uses the Wallis product when they actually need digits of pi. Wallis is for the journey.
References
- Wallis product on Wikipedia. The original formula from 1655 and the proof.
- Sheldon Leemon, Mapping the Commodore 64 (COMPUTE! Books, 1984). Pages 212-232 cover the BASIC ROM floating-point engine: FAC/ARG accumulators, the 5-byte format, and every entry point.
- C64 floating-point arithmetic on the C64 Wiki. Quick reference for the ROM routine addresses and calling conventions.
- TMPx syntax reference. Assembler syntax used in the article.
Happy Pi Day.