A little more speed from the 6502
By Michael Doornbos
- 4 minutes read - 849 wordsCan we get a little more speed from a 6502 than we did last week? Almost certainly.
The memory test we used was a general-purpose one. It’s flexible and reusable. The price is some speed. Let’s try and make it faster.
The test machine for this one

I’m going to rerun the test on a Corsham KIM-1 Clone for a couple of reasons:
- It’s still on my desk from last time
- It’s clocked at EXACTLY 1Mhz
- It has a large block of contiguous memory available if we want it without ROMs , etc. getting in the way.
- The memory expansion is connected directly to the bus, making the “expansion” the same access speed as the built-in memory
- It doesn’t compete with other devices (I’m looking at you, video chips!), so we’re just talking 6502 and memory here.
And by clocked at EXACTLY 1Mhz, assuming the frequency counter in my scope is pretty accurate:
1.000000Mhz ;-)
As a refresher, the program, which is nice and flexible and speedy enough for many purposes, was:
.org $0200
source .equ $2000
dest .equ $3000
len .equ $0400
from .equ $00
to .equ $02
tmpx .equ $04
cld
lda #$ff
sta $1603
sta $1601
copyr
lda #<source
sta from
lda #>source
sta from+1
lda #<dest
sta to
lda #>dest
sta to+1
ldy #0
ldx #>len
beq remain
next lda (from),y
sta (to),y
iny
bne next
inc from+1
inc to+1
dex
bne next
remain ldx #<len
beq done
nextr lda (from),y
sta (to),y
iny
dex
bne nextr
done
lda #$00
sta $1601
end
brk
Using a scope on the PA0 pin on the KIM-1 we can get a very accurate (not perfect) time on this routine.
And we clocked it in a 16.60ms to complete on the 1Mhz 6502.
So a 1024 byte transfer is about 61.7 kb per second.
Unroll the thing
One very common use on an 8Bit machine would be a memory copy to the screen memory location. Maybe as part of a background change in a game, something along those lines.
So let’s do exactly that. We’ll use 1024 bytes here so that it’s precisely 4 - 256 byte pages. We’re going for speed for real now; not crossing page boundaries will help.
.org $0200
source .equ $2000
dest .equ $3000
cld
lda #$ff
sta $1603
sta $1601
ldx #$00
copyr
lda source,x
sta dest,x
lda source+256,x
sta dest+256,x
lda source+512,x
sta dest+512,x
lda source+768,x
sta dest+768,x
dex
bne copyr
done
lda #$00
sta $1601
end
brk
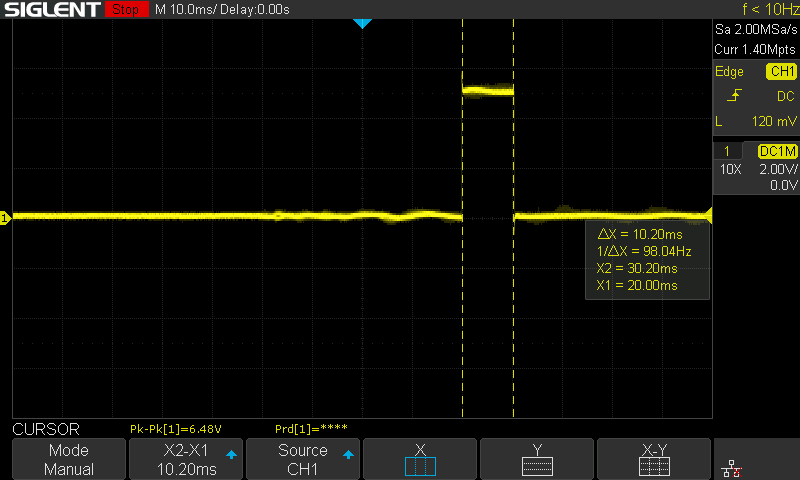
This works out to 100392 bytes or 100.4kb per second. Getting better…
Unroll further?
What about if we break it into 64-byte chunks?
.org $0200
source .equ $4000
dest .equ $5000
cld
lda #$ff
sta $1603
sta $1601
ldx #$40
copyr
lda source,x
sta dest,x
lda source+64,x
sta dest+64,x
lda source+128,x
sta dest+128,x
lda source+192,x
sta dest+192,x
lda source+256,x
sta dest+256,x
lda source+320,x
sta dest+320,x
lda source+384,x
sta dest+384,x
lda source+448,x
sta dest+448,x
lda source+512,x
sta dest+512,x
lda source+576,x
sta dest+576,x
lda source+640,x
sta dest+640,x
lda source+704,x
sta dest+704,x
lda source+768,x
sta dest+768,x
lda source+832,x
sta dest+832,x
lda source+896,x
sta dest+896,x
lda source+960,x
sta dest+960,x
dex
bpl copyr
done
lda #$00
sta $1601
end
brk
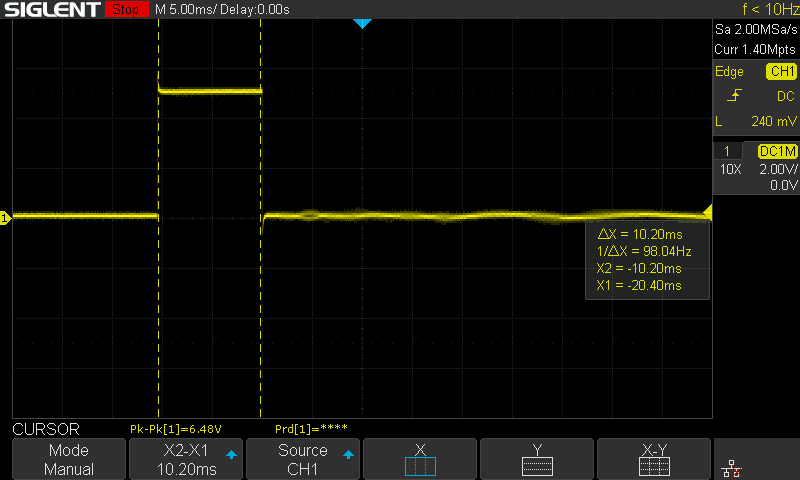
Looks the same. Let’s move on.
No, REALLY unroll it; this is getting ridiculous
If we eliminate the loop and unroll it completely, we end up with:
.org $2000
source .equ $4000
dest .equ $5000
cld
lda #$ff
sta $1603
sta $1601
lda source
sta dest
lda source+1
sta dest+1
lda source+2
sta dest+2
lda source+3
sta dest+3
lda source+4
sta dest+4
lda source+5
sta dest+5
lda source+6
;;; 20 minutes later... I'm not pasting the whole thing;;;
lda source+1018
sta dest+1018
lda source+1019
sta dest+1019
lda source+1020
sta dest+1020
lda source+1021
sta dest+1021
lda source+1022
sta dest+1022
lda source+1023
sta dest+1023
done
lda #$00
sta $1601
end
brk
We save a couple of clock cycles per LDA and STA line, and what… 5 for each loop? (something like that).
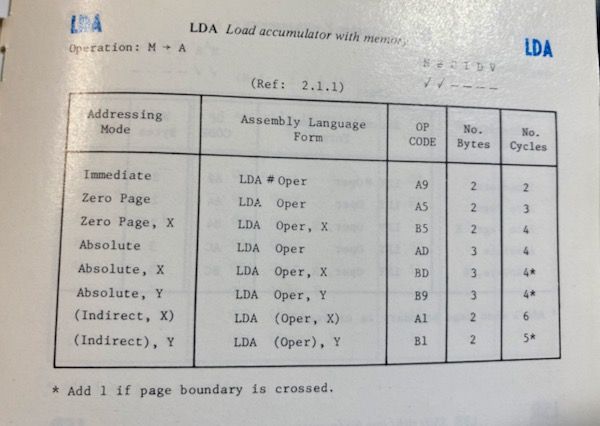
p 153 of the VIC-20 programmers reference guide
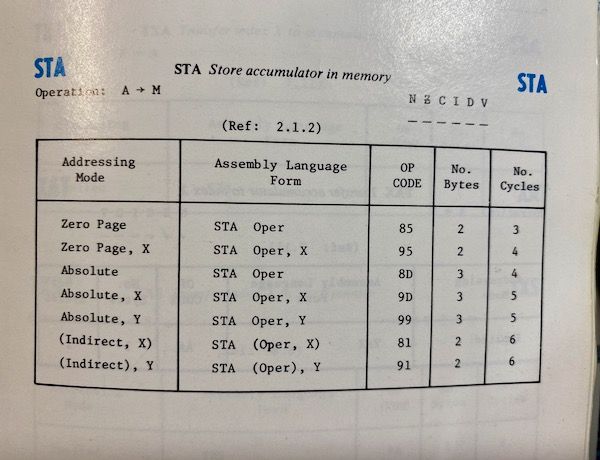
p 159 of the VIC-20 programmers reference guide
And it IS faster:
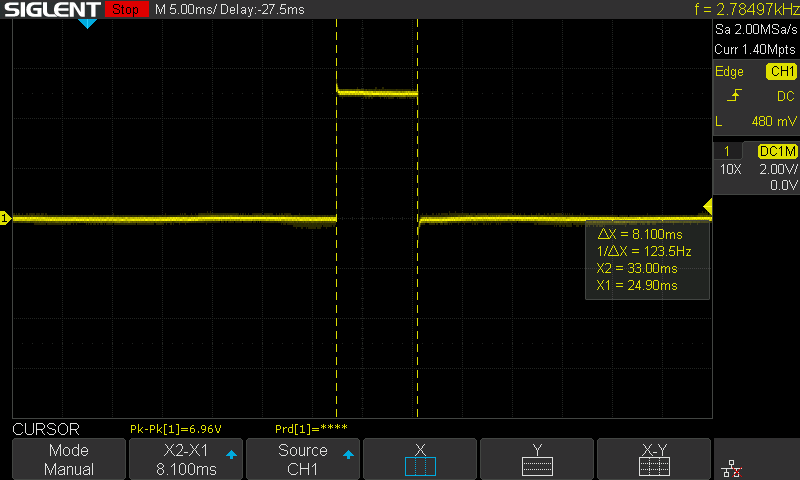
The price we pay is that it’s now a 6159-byte long program to move 1024 bytes (fits from $2000 to $380f). But it sure is fast!
126.4 Kb per second.
After chatting a little with Robin, he mentioned that this technique, or something like it, is used in many demos that push on what vintage hardware can do. Some coders generate this code at runtime to save some space. Pretty neat.
Can you do it better, or do it in a more interesting way?
My challenge to you is:
Have some fun trying to make this 1024-byte copy faster or get it close to this performance in an exciting way. Also, let’s see it implemented on other 6502-based machines. Surely the Atari and Apple II peeps out there want to give this a go, right?
Maybe a self-modifying code example (I don’t care for self-modifying code, but knock your socks off!).
Just remember to have fun. You don’t have to show anyone up; this is about learning and exploring.